PLAI @ USENIX Security'25 in Seattle
Tristan Benoit presents BLens, our latest work on function labeling on Friday, August 15
11.08.2025
Tristan Benoit will present our paper "BLens: Contrastive Captioning of Binary Functions using Ensemble Embedding," joint work with Yunru Wang and Moritz Dannehl at USENIX Security this week. Brief summary below:
Binary reverse engineering is hard, but having useful names for functions helps. As names are usually stripped, one hope is to generate plausible names using machine learning models for binary code. But state-of-the-art models based on the paradigm of translating from assembly to natural language names struggle with generalizing due to distribution shifts between projects and may generate misleading names.
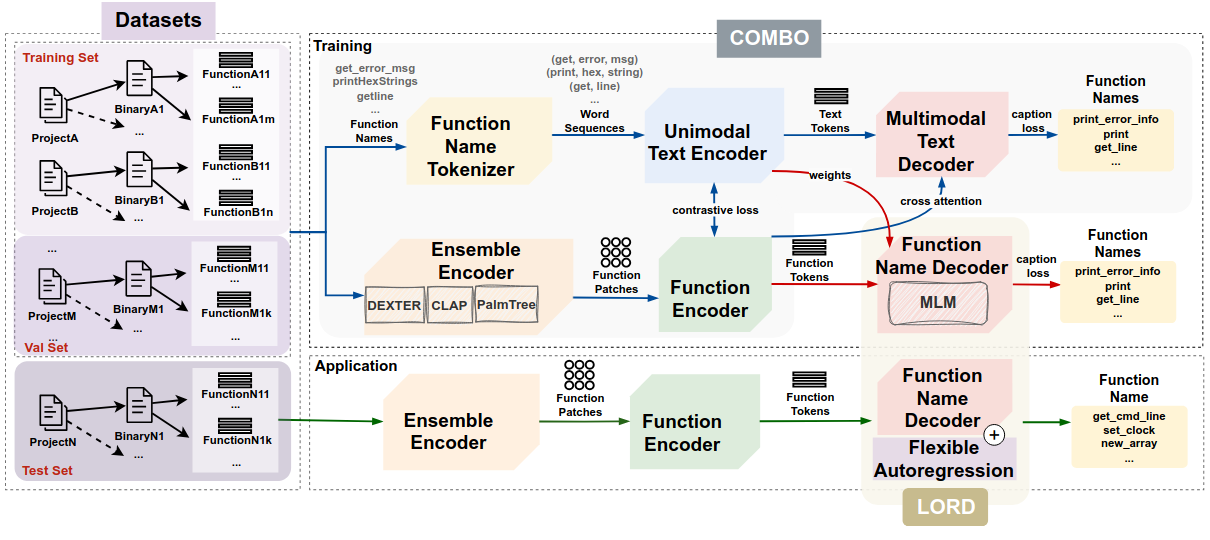
The intuition behind BLens is that generating a function name from assembly code is more similar to image captioning than it is to translation between languages. Assembly is a different modality to function names, characterized by low information density and high redundancy. Inspired by the state-of-the-art multimodal image-text model GIT (J. Wang et al.), we embed functions into patches using three pre-trained function embeddings (DEXTER, CLAP, and PalmTree).
Building on the contrastive captioning paradigm pioneered by CoCa (Yu et al.), our pre-training phase (COMBO) trains the model not only to generate function names but also to associate a learnable name representation with the corresponding function embedding. This dual objective enables robust training and helps the model generalize across distribution shifts.
During fine-tuning, we train our novel function name decoder LORD using a masked language modeling objective. At inference, LORD considers tokens at all positions and predicts them in decreasing order of probability in a flexible autoregression scheme, stopping once it drops below a threshold. This threshold is calibrated on a validation set to maximize the F1 score, reducing false positives even under distribution shifts.
Even on unseen projects, BLens delivers a significant improvement over previous methods, achieving a 42% increase in F1 score, as well as improvements on metrics like RougeL, Bleu, and VarCLR. Performance metrics tell only part of the story, however, as the usefulness of predicted function names is difficult to measure. Our paper includes several case studies where we demonstrate on the original source code that even function names that count as mispredictions can provide valuable and meaningful information to a reverse engineer.